
Twitter has introduced the Academic Research Track program for providing academic researchers free access to the full history of public conversations through their full-archive search endpoint. Access to full-archive was previously limited to only paid subscribers. The Twitter API v2 had limitations on the number of tweets that could be pulled every month: researchers were allowed to pull only 500k with the counter resetting every month for a fresh new quota. However, this limit has been pushed to 10 million in the Academic Research Track.
Besides these benefits, researchers are also provided with more precise filtering capabilities with the Academic Research Track.
Where to apply for Twitter’s Academic Research Track?
Here’s the link to the application which you’ll need to fill irrespective of your developer account status: new or existing. You are eligible for the track if you are one of the following: master’s student, doctoral candidate, post-doc, faculty, or research-focused employee at some educational institute or university.
Twitter API v2
Unlike previous versions of Twitter API, v2 presents a very minimal payload. In previous versions, the complete tweets data dictionary would be present in the payload. Suppose I need to work on just the tweet text and the location data, I would have been presented with all the tweet objects and I had to save/process the incoming payload as per my preference. There is a waste of bandwidth, isn’t it?
In v2, by default, only the tweet text and identifier are presented; therefore, researchers will have to manually ask which tweet objects (entities) to include in the payload using a set of expansions and field options. If you want to know more about expansions and field options please go through these official pages (expansions/fields).
Searching historical tweets using twarc
twarc2 (v2 of twarc) is a python library that lets you access Twitter API without having to have a thorough understanding of how the new payload works in Twitter API v2.
twarc can be used for multiple tasks while working with Twitter API. It can be used both as a command-line tool and a library. My preference is task-specific. While searching tweets I prefer using it as a command-line tool. The commands are simple to use/remember. And while hydrating tweet IDs (extracting complete tweet information using tweet ID), I prefer using it as a library.
In this post, I’ll discuss how the newer version of twarc i.e. twarc2 can be used to search for historical tweets. Researchers with approved Academic Research Track can access Twitter data as older as 2006. Not all academicians have sufficient funding to pay for premium endpoints. Thanks to Twitter for understanding the need of academic researchers.
Getting started with twarc2
Let’s install twarc.
#installing pip3 if already not installed $ sudo apt install python3-pip #installing twarc $ pip3 install twarc
Once twarc is installed, you’ll need to configure it to connect to Twitter API (using bearer token/API keys).
$ twarc2 configure
twarc will ask you to enter your bearer token, and API keys (optional). Just enter your bearer token which is available on the Twitter Dev platform under an application that is approved for Academic Research Track. Proceed ahead by entering your bearer token.
Not that twarc is configured, it’s time to search for tweets.
Searching for historical tweets is quite straightforward. The usage is something like the below:
$ twarc2 search query [command] > [output file]
Here are some examples for better understanding.
Let’s search for tweets that have the words “corona” and/or “covid” in their tweet body.
$ twarc2 search '(corona, OR covid)' > tweets.json
The above command however searches for tweets that were created in the last 7 days.
For extracting tweets older than 7 days, you’ll have to provide the --archive--start-time (%Y-%m-%d or %Y-%m-%dT%H:%M:%S)--end-time (%Y-%m-%d or %Y-%m-%dT%H:%M:%S)
$ twarc2 search '(corona, OR covid)' --archive --start-time 2020-05-10 --end-time 2020-05-20 > tweets.json
The above command will search for tweets that were created between May 10, 2020 (UTC), and May 20, 2020 (UTC), and contain the words “corona” and/or “covid”. The incoming JSON will be then saved to tweets.json.
How to write a Twitter search query?
Well, this should not be a problem if you make yourself comfortable with the advanced search tool that is available on Twitter Web.
Head out to Twitter and search for anything you’re interested in, using the search bar at the top-right corner. To start with, let me search for “corona”. On the next page, you’re presented with your search results. On the right sidebar, you’ll have an option for Advanced search. Click on it.
You’ll now be presented with a window as shown below.
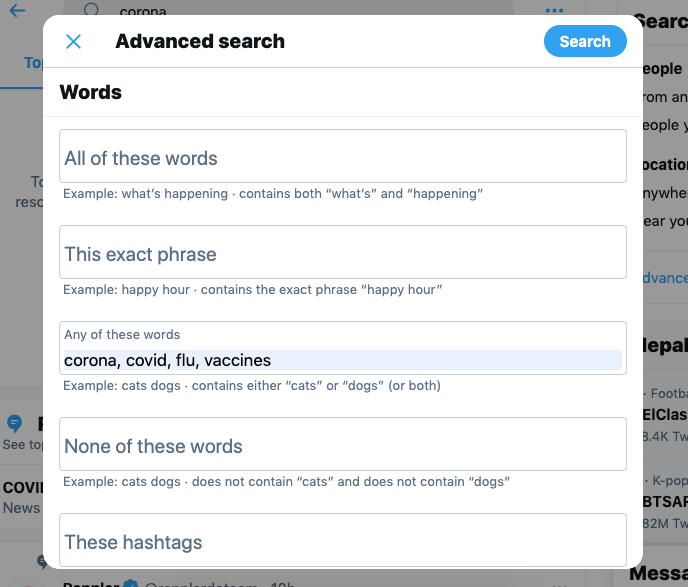
Now fill out the search fields as per your needs. Scroll down and you’ll have a wide range of fields you can deal with. Let’s choose language as EN (just as an example). Once you’re done filling out the fields, you’ll be presented with the query on the top search box.
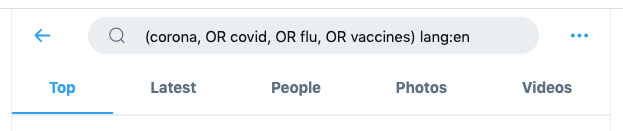
You can now copy and paste the provided query into the query section of twarc. Keep the generated query within quotes (increases readability too).
This way you can have Twitter generate complex queries for you. And from there, you can use the generated query with twarc and pull the tweets as per your conditions.
What else commands does twarc provide?
There are --since-id--until-id
You also have --limit
For more information, please visit the official documentation page of twarc.
I hope this quick guide on using twarc2 to access Twitter API v2 was useful. I’ll see you at the next one. Have a good day.